
Loosing my conversion
La conversion d’unité est en soi une activité assez peu intéressante mais qui reste fondamentale et quasi-quotidienne. Nous avons tous eu à rechercher, au moins une fois dans notre existence, une erreur dans nos codes qui n’était liée qu’à une bête erreur de conversion d’unité. Dans un contexte de travail international, cette nécessité est renforcée, car les unités du Système International (SI) ne sont pas universellement employées, en particulier dans l’agronomie et notamment par nos amis et clients américains.
Il est donc fondamental de se doter d’une librairie robuste de conversion d’unités, utilisable dans tous nos projets. La transversalité organisée dans le pôle agronomie d’itk vise à assurer une vie scientifique, harmoniser les pratiques entre équipes et mettre à leur disposition des avancées particulières, afin que chacune n’ait pas à réinventer la roue de son côté.
C’est donc tout naturellement qu’un atelier transverse a été créé pour identifier une librairie Python de conversion d’unités adaptée à nos usages. Cette librairie a pour vocation d’être le pendant d’une fonction Matlab créée il y a quelques années pour assurer un rôle équivalent dans nos vieux codes développés dans ce langage.
Les objectifs : une librairie simple et naturelle d’emploi, adaptée à notre métier et facile à faire évoluer
La fonction Matlab que nous sommes habitués à utiliser, développée en interne en 2014, est assez simple d’emploi.
Jugez plutôt :

La première entrée est la valeur à convertir, la deuxième l’unité d’origine et la dernière l’unité cible. La sortie est la valeur dans l’unité cible.
Nous vérifions bien qu’un coureur qui termine un 100m en 10 secondes (soit une vitesse de 10 m/s) court à 36 km/h de moyenne. Nous voyons que nous pouvons indiféremment utiliser la notation « m/s » ou « m.s-1 » pour m.s-1. Nous voulions conserver ce genre de facilité.
Autre point important, la fonction informe respectueusement mais fermement l’utilisateur qu’il fait n’importe quoi quand cela se produit :

Les utilisateurs sont parfois étourdis, il faut veiller à le leur dire avec la courtoisie qu’il convient.
Enfin, nous voulions conserver une spécificité liée à notre travail en agronomie, qui est la conversion des rendements. Actuellement, les pays européens, et notamment la France, utilisent des unités de masse rapportées à la surface récoltée : par exemple le quintal à l’hectare (« q/ha »). Aux Etats-Unis en revanche, l’utilisation d’unités de volume rapportées à la surface est restée prédominante. Le boisseau (« bushel » en anglais) à l’acre est fréquemment rencontré.
On ne peut pas à proprement parler ici de conversion d’unité puisqu’il s’agit d’un changement d’unité qui passe par l’emploi d’un coefficient de masse volumique, improprement appelé en agronomie (mais l’agronomie, c’est sale, il y a de la terre dedans) le poids spécifique.
Or, le poids spécifique est un des indices de qualité de la récolte et peut varier selon les situations. Nous utilisons donc par défaut des coefficients standards, définis par culture :
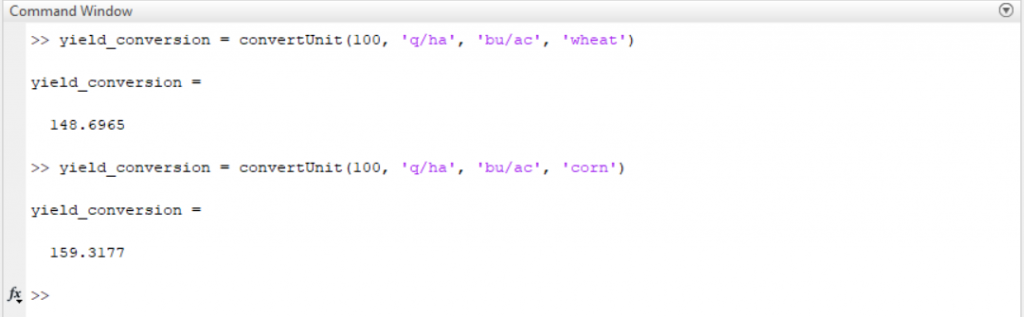
On peut se demander si ce genre de calculs a sa place dans une fonction de conversion d’unité, mais c’est pratique. Et si c’est pratique, c’est qu’il existe un besoin et autant bien gérer ce besoin.
L’idée de base de la fonction Matlab est assez simple : l’unité d’entrée et l’unité cible sont toutes deux converties en unités SI et on détermine un coefficient de conversion qui permet de passer de l’unité d’origine en unité SI. Puis il suffit d’utiliser le ratio de ces deux coefficients pour trouver la valeur dans l’unité cible. Comme la phrase qui précède n’est pas forcément limpide, reprenons l’exemple de conversion de la vitesse : nous souhaitons convertir 10m/s en km/h.
L’unité d’entrée est le « m/s », qui est l’unité SI, cela tombe bien. Une table nous dit que, pour convertir des m en m, il faut multiplier par 1 et que pour convertir des s en s, il faut multiplier par 1. Comme on a le séparateur « / », il faut diviser 1 par 1 pour obtenir le coefficient de conversion de « m/s » en « m/s » : 1, ça marche ! Ouf !
L’unité cible est le « km/h », ça devient un tantinet plus rock’n roll. Oh, juste un brin. La même table nous dit que pour convertir des km en m, il faut multiplier, comme chacun sait, par 1000. Pour convertir des heures en secondes, il faut multiplier par 3600. Comme on a le séparateur « / », on sait qu’il faut diviser 3600 par 1000 pour obtenir le coefficient de conversion des « m/s » en « km/h » et au passage on vérifie que les unités d’entrée et cible sont bien homogènes puisque leur unité SI correspondante est le « m/s » pour toutes deux.
Il nous suffit enfin de multiplier le 10 qui est la valeur en entrée par le coefficient de conversion pour obtenir 36 qui est la vitesse en km/h.
Nous n’avons donc besoin que d’une table qui convertit toutes les unités dans leur équivalent SI, pour toutes les dimensions. Il n’y en a pas tant que cela (longueur, surface, volume, masse, temps, pression, énergie, angle, force, puissance). Pour les températures, c’est un peu plus compliqué puisqu’il faut utiliser une relation linéaire pour passer des K ou °C en °F.
A partir de cette base, il devient très facile de rajouter tout un panel d’unités comme le furlong, si on en a besoin, parce que les systèmes anglo-saxons sont très riches en unités de mesure. Et non, le furlong n’est pas utilisé que par les Hobbits.
Le but de l’atelier était donc de développer une librairie Python qui reproduise ce fonctionnement.
Attendez, on avait dit de ne pas réinventer la roue !
Dites, Python est un langage connu pour la richesse de ses librairies, donc ne me dites pas qu’il n’existe pas déjà des librairies qui permettent de convertir facilement des unités !
Saperlipopette !
Nous avons recherché l’existant et n’avons pas trouvé ce que nous recherchions :
- beaucoup de librairies très riches utilisaient des objets comportant la valeur et l’unité, ce qui permet de connaitre la valeur en n’importe quelle unité. Ce n’était pas ce que nous recherchions puisque nous préférions continuer à manipuler des entiers ou des flottants, plutôt que des objets contenant l’unité ; l’emploi d’une de ces librairies nous aurait obligés à modifier tous nos codes et les aurait alourdis ;
- d’autres librairies renvoient des chaines de caractères desquelles il faut extraire la valeur : pas très pratique ;
- d’autres imposaient de faire beaucoup d’imports, ce qui aurait eu des répercussions sur la gestion des paquets et des environnements et aurait en outre alourdi le code ;
- d’autres enfin ne géraient pas les températures ;
- aucune ne gérait les conversions d’unités de rendement, mais on ne peut pas franchement leur en vouloir.
On ne peut pas complètement nier non plus que cela nous démangeait de faire notre librairie, parce que le problème est rigolo et que cela nous permet de la faire évoluer à notre guise.
Nous nous sommes donc lancés dans le développement d’une librairie Python, ce qui a aussi été le prétexte d’expérimenter une autre façon de travailler.
Le XP par l’exemple : TDD et mob-programming
Une fois l’atelier transverse lancé, c’est-à-dire une équipe de six personnes constituée et une date de début des opérations fixée, nous avons décidé d’expérimenter une façon de travailler que nous mettons rarement en œuvre : le mob-programming et le Test Driven Development, ou TDD.
Qu’es acò, le mob-programming et le TDD ?
Il s’agit de deux pratiques faisant partie de ce que l’on appelle l’XP-Programming. Vous voilà bien avancés !
Plus spécifiquement, le mob-programming, c’est :

Merci Woody. Des esprits brillants, c’est tout nous.
Bon, évidemment, il n’était pas question de confinement à l’époque. C’était il y a un moment déjà.
Certains esprits sceptiques objecteront derechef que tout ceci ne semble pas bien productif. On pourrait rétorquer que c’est plutôt écologique et économique puisqu’on n’utilise qu’un seul ordinateur, mais les vertus généralement attribuées au mob-programming sont les suivantes :
- meilleure qualité du code ;
- meilleur partage du code ;
- meilleure productivité quand la technique est bien maitrisée.
Comme il ne s’agit pas du sujet de ce billet et que l’internet fourmille de documentation sur le thème, je vous renverrai, par exemple, à cette interview de Woody Zuill.
Le TDD quant à lui consiste à écrire d’abord un test, faire en sorte que le test passe en écrivant le code minimal, remanier le code, vérifier que les tests passent toujours et écrire un nouveau test qui ne passe pas. Là aussi, le sujet est très bien documenté sur la toile, par exemple ici.
Comment nous fîmes
Nous avons fait deux sessions de TDD en mob-programming (la foule étant, comme nous l’avons vu, composée de six personnes, ce qui en fait une foule relativement limitée).
Chaque session a connu trois grandes étapes :
- mise au point des règles de fonctionnement ;
- session de travail (la partie la plus longue de la journée, évidemment) ;
- bilan et pistes d’amélioration.
Les règles de la première session étaient :
- langue parlée : anglais, français, franglais, …
- une pause de 5 minutes toutes les heures (et non pas l’inverse) ;
- TDD ;
- un ordinateur ;
- un binôme Pilote-Copilote sur cet ordinateur ;
- un pool, constitué des développeurs qui ne sont ni Pilote ni Copilote, à un instant donné ;
- les développeurs dans le pool ne s’expriment qu’après un certain délai ou sur demande explicite du binôme Pilote-Copilote ;
- les rôles tournent une fois que le pilote a codé la solution à un test qui échouait, puis un nouveau test qui échoue ;
- rotation : vieux du pool à Copilote à Pilote à jeune du pool ;
- pas de gros mots (cela a sans doute été la règle la plus enfreinte, notamment par un individu en particulier).
Les règles ont un peu évolué lors de la seconde session, notamment sur la gestion des rotations, le binôme étant renouvelé intégralement à chaque changement (ce qui, dans le contexte sanitaire actuel, apparait comme une hérésie).
Nous avons gardé préciseusement des images photographiques du tableau sur lequel furent rédigées ces règles et nous vous les reproduisons ici pour vous procurer la saveur de l’authentique, avec de vrais morceaux de jus de cerveau dedans :

Comme vous pourrez le constater, les règles de politesse ont été précisées…
Nous avons essayé, dans toute la mesure du possible, de réfréner notre impatience bien légitime et naturelle de nous jeter bille en tête dans le code en nous mettant d’accord au préalable sur la structure du code et son principe.

Et voilà le résultat !
convert_unit : faisons le tour du propriétaire
Reprenons nos exemples déjà vus avec le code Matlab.

Comme nous le voyons, il suffit d’importer une fonction de notre paquet, et notre coureur court toujours à 36 km/h de moyenne sur un 100m. Bravo à lui et à nous !

Notre librairie Python nous informe elle aussi que les kg et les inch n’ont rien à voir avec la choucroute et en plus elle fait un peu d’humour, ce qui ne peut pas faire de mal.
Pour convertir des unités de rendement, il faut importer une autre fonction, histoire d’être bien sûr de savoir ce que l’on fait :
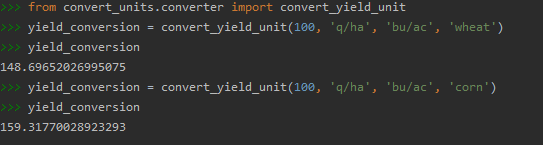
Et nous constatons que nous obtenons bien les mêmes valeurs qu’avec la fonction Matlab.
Nous avons comme projet de faire évoluer cette librarie spécifique, en rajoutant la conversion des rendements secs en rendements humides, activité simple mais suffisamment routinière pour qu’elle comporte des risques d’erreur, ou le passage de rendements volumiques à des rendements massiques en utilisant des masses volumiques mesurées plutôt que standards.
Ah, et, comme de bien entendu, nous pouvons manipuler des listes, ce qui permet d’éviter de faire des boucles disgracieuses :
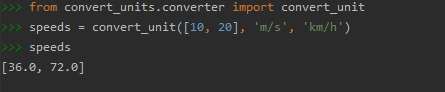
Notch, draw, loose! Lâchons convert_unit
Comme nous sommes satisfaits des fonctionnalités de cette librairie et convaincus de son intérêt dans le développement de modèles numériques manipulant des grandeurs physiques, nous la mettons à disposition sur anaconda cloud sur le channel itk :
- https://anaconda.org/itk/convert_units
- ou conda install convert_units -c itk.
Bien que seul le paquet soit mis à disposition pour le moment, nous avons pour objectif de déposer l’ensemble du code source sur une plateforme de développement publique, type github.com, pour permettre à chacun de contribuer à son enrichissement. En attendant, la documentation de cette librairie a été compilée en pdf et peut être téléchargée en suivant ce lien :
Nous espérons que cette librairie pourra rendre service à la communauté et nous sommes naturellement preneurs de tout retour.
Lucile, Davide, Jonathan, Rami, Romain, Vianney
Petit jeu : dans le nuage de mots ci-dessous, des mots qui ne sont pas des unités se sont glissés.
Saurez-vous les retrouver ?

Super boulot, on aimerait la même en JavaScript 🙂 Si on a le temps un jour, on essaiera de s’appuyer sur vos travaux. Très sympa le concept du mob-programming 😉