Résorption de dette technique : on commence par la documentation
L’été étant propice à prendre un peu de recul, voici un deuxième volet de la série consacrée aux enablers dans le pôle agronomie et modélisation. Celui-ci est consacré à la réappropriation du modèle Vintel via la réécriture de la documentation aux normes actuelles.
Le but
Vintel est un des tout premiers outils créés à itk : les prémices du projet datent de 2009 et autant dire qu’il en est passé du monde sur le code ! Comme tout projet ancien chez nous, il a été codé en Matlab. Il tourne bien, n’a pas de bug (en tout cas, nous n’en avons pas décelé depuis longtemps) et accompagne des viticulteurs un peu partout en France et en Europe dans leur gestion hydrique de la vigne.
Alors, quel est le problème ?
Les vieux qui ont conçu le modèle et l’ont développé sont soit partis vers d’autres aventures, soit occupent d’autres fonctions (soit ont occupé d’autres fonctions avant de partir vers d’autres aventures, ce qui revient à peu près au même pour le sujet qui nous occupe). Alors place aux jeunes ! Quand on n’a pas conçu un modèle, pour se l’approprier, soit on lit la documentation, soit on se plonge dans le code ; l’idéal étant de faire les deux car la documentation, en ce qui concerne un modèle, éclaire et explique plus que le code les choix de modélisation faits et donne une vision globale ; le code, quant à lui, est la référence de ce qui est fait. Rentrer dans un modèle par le code seul peut s’avérer aride et peut conduire à passer à côté de choses.
La documentation qui avait été créée à l’époque était très bien faite et riche, mais elle souffrait de deux problèmes :
- elle n’avait pas toujours été mise à jour, même si les grands principes restaient vrais ; elle ne représentait donc plus exactement ce qui existe dans le code. C’est une forme de dette technique
- elle était rédigée essentiellement sur des éditeurs de textes, alors que la nouvelle norme interne de documentation, plus pratique, regroupe tout en ligne sur ce que nous appelons Agrodoc et qui est accessible assez facilement à toute l’entreprise en interne.
Cette documentation interne comporte trois parties :
- un aperçu rapide du modèle qui permet de comprendre ce qu’il peut faire, quelles sont ses entrées et ses sorties essentielles. Ce niveau de détail est intéressant par exemple pour nos commerciaux qui n’ont pas à connaître le cœur du modèle mais qui peuvent bénéficier de ce niveau de connaissances.
- la deuxième partie rentre dans les détails des formalismes, donne les références bibliographiques utilisées et indique les équations et principes de fonctionnement des modules. Nous entendons ici par module une sous partie d’un modèle qui décrit un formalisme en particulier (par exemple, la phénologie). Cette notion est parfois ambigüe car un module peut être lui-même composé de plusieurs sous-modules
- la troisième partie décrit l’architecture du code grâce à Sphinx qui lit et met en forme les docstrings de Python
Le but de cet enabler était donc de mettre à jour la documentation de Vintel dans Agrodoc en ce qui concerne les deux premières parties : le code étant encore en Matlab, la troisième partie ne pouvait pas être faite de façon simple et n’avait pas lieu de l’être. Cela a été fait en s’appuyant à la fois sur l’ancienne documentation pour réutiliser des schémas, connaître les grands principes et les références bibliographiques, et sur le code pour être à jour de ce qui est réellement fait par le modèle.
De l’archéologie au plan
Pour faire de la bonne documentation sur un projet ancien, il s’agit déjà de faire un peu d’archéologie et d’exhumer les anciennes documentations. Il ne faut donc pas avoir peur de la poussière (virtuelle). Il s’est ensuite agi de faire un schéma conceptuel du modèle qui décrit à la fois l’architecture du code et les principes de fonctionnement du modèle.

Il faut dire que dans le milieu de la modélisation agronomique, on aime bien les schémas avec des boîtes liées par des flèches. Heureusement, nos glorieux prédécesseurs avaient déjà fait un schéma dans le goût. Nous le mettons ici en flouté car le propos n’est pas de rentrer dans le détail, mais de parler des principes.
Nous voyons sur ce schéma qui représente le modèle que nous avons des entrées, dans les rectangles blancs à gauche (les informations dont le modèle a besoin pour fonctionner), des modules qui communiquent entre eux et qui sont, à leur échelle, des petits modèles (les différentes boîtes) et dont les sorties alimentent d’autres modules ou constituent les sorties du modèle, c’est-à-dire ce que l’on cherche à prédire (par exemple, le niveau de stress hydrique de la vigne ou le contenu en eau du sol).

Ce schéma tient lieu de plan d’orientation dans le modèle et de table des matières de la documentation. Et comme dans toute bonne dissertation, une fois le plan fait, le reste vient tout seul ! Ou presque.
Fonctionnement en mode projet
Comme les enablers sont conduits en mode projet, ce plan a été utilisé pour faire le backlog de ce projet, à savoir la liste priorisée des tâches à faire pour mener à bien le projet.
Puis les tickets ont été travaillés par des binômes en se bloquant des créneaux de travail ou seul. Pour chaque ticket, les étapes suivies étaient :
- Compréhension du module
- Modèle conceptuel du module si sa complexité le justifie
- Rédaction de la documentation avec les références bibliographiques
- Liens vers les autres parties de la documentation (ce qui a nécessité une passe finale pour harmoniser et vérifier les liens)
L’intérêt de travailler en binôme ici est multiple : quand on a affaire à du code que l’on ne maîtrise pas et qui a été établi selon d’anciennes normes et qu’on doit le confronter à de la documentation qui est tout aussi ancienne (voire plus), se mettre à deux cerveaux peut permettre de se clarifier les idées (et de se soutenir). En travaillant à deux également, on s’assure que ce que l’on écrit peut être compris par une autre personne. Enfin, on a au moins deux personnes qui connaissent bien le module et son contenu. Enfin, pour finaliser, une revue a été faite par une personne extérieure au binôme (un calcul savant vous apprendra qu’il fallait être au moins trois pour ce travail) avec comme objectif de vérifier que la rédaction était bien compréhensible et d’harmoniser les différentes parties entre elles (l’harmonie, c’est la vie).

Le résultat
Le résultat de se travail est une documentation en ligne au standard actuel, au moins pour les deux premières parties sur les trois décrites ci-dessus (aperçu rapide et détail des formalismes) : pour l’architecture du code, il va falloir attendre la retranscription du code en Python.
Cette documentation est utilisable pour les personnes qui rejoignent le projet et à toutes les occasions où l’on est amené à se poser des questions sur le modèle ou le code : pour répondre à des questions de support (que ce soit en direct ou pour aider l’équipe support à répondre à des clients), pour parler du modèle à l’extérieur en se basant sur du tangible, pour s’inspirer de ce qui a été fait dans Vintel sur d’autres projets, … Enfin, et peut-être surtout, cela a permis à une nouvelle génération de s’approprier les concepts et le code du modèle.
Quelle pourrait-être la suite ?
Cette étape de réappropriation des connaissances par la documentation était aussi nécessaire en vue d’une traduction du code initial Matlab en Python.
Mais pourquoi vouloir traduire un code qui fonctionne bien ? La réponse n’est pas à chercher du côté économique et c’est du reste pour cette raison que la traduction tarde : en effet, le temps de travail nécessaire à une traduction génère un coût bien supérieur aux économies permises par un abandon des licences.
Comme toute dette technique, car c’est ce dont il s’agit vu les choix qui ont été faits, nous avons affaire à des coûts cachés auxquels il est intéressant de s’attaquer :
- Temps de formation : toute personne arrivant dans le pôle est amenée à sa familiariser à la fois à du code Matlab et Python et aux architectures internes qui vont avec. Or, la vocation première de notre métier n’est pas dans la technique mais dans la modélisation, la technique n’étant qu’un outil au service de la modélisation
- Temps consacré à des tâches techniques et à maintenir de vieux codes : autant de temps qui empêche de se focaliser sur le vrai sens de notre métier (« comment répondre aux besoins actuels de l’agriculteur ? »)
- Temps consacré au développement et au maintien dans deux langages du code « autour des modèles », soit celui qui permet de faire des analyses de sensibilité, de paramétrer les modèles et d’interagir avec les interfaces utilisateurs et les bases de données : là encore, nous sommes dans la technique et tout ce qui peut limiter le temps qui y est consacré est bienvenu pour se focaliser sur le cœur de notre métier
- Temps consacré à s’approprier de la culture technique d’un projet lors d’un changement d’équipe : les changements d’équipe sont inévitables, voire souhaitables dans une certaine mesure pour renouveler les idées, remotiver, prendre du recul, bénéficier d’un regard neuf ou doté d’une autre expérience. Ces changements de projet seront d’autant plus efficaces et rapides que la technologie ne sera pas un obstacle : n’oublions pas que notre métier n’est pas la technique mais de savoir comment mettre la science au service du monde agricole !
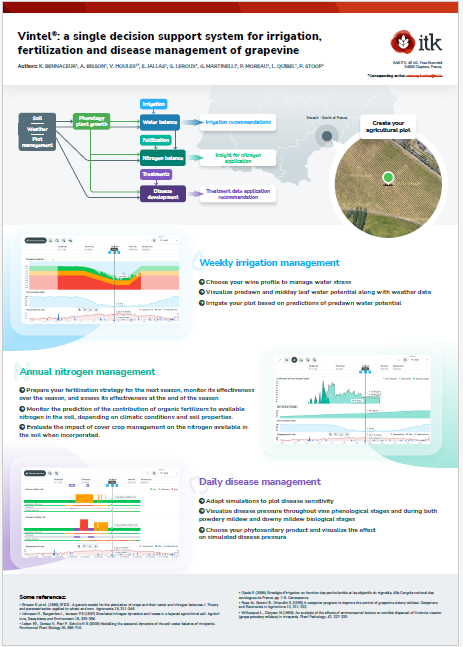
Enfin, et pour finir, une des premières conséquences de ce travail de réappropriation a été notre participation au congrès du Giesco pour y présenter Vintel sous forme de poster à la communauté scientifique spécialisée dans la viticulture et l’œnologie.