
COVID-19, data intelligence et modélisation : le difficile passage de la donnée à l’information et à la prévision
L’épidémie de COVID-19 pose de nouveaux défis inédits à nos sociétés modernes : comment prévoir le développement de cette pandémie et trouver très rapidement les meilleurs moyens pour l’enrayer ? La collecte mondiale des données épidémiologiques et leur mise à disposition transparente et quotidienne, se sont organisées dans des délais record, et tous les citoyens ont désormais accès sur le Web à une foule de visualisations des principales statistiques sur la maladie. Les données sont bien là, mais peut-on en dire autant de l’information ?
La visualisation des données : une clé essentielle pour une bonne compréhension
Le site de référence sur ce sujet est celui de la John Hopkins University (JHU) à Baltimore :
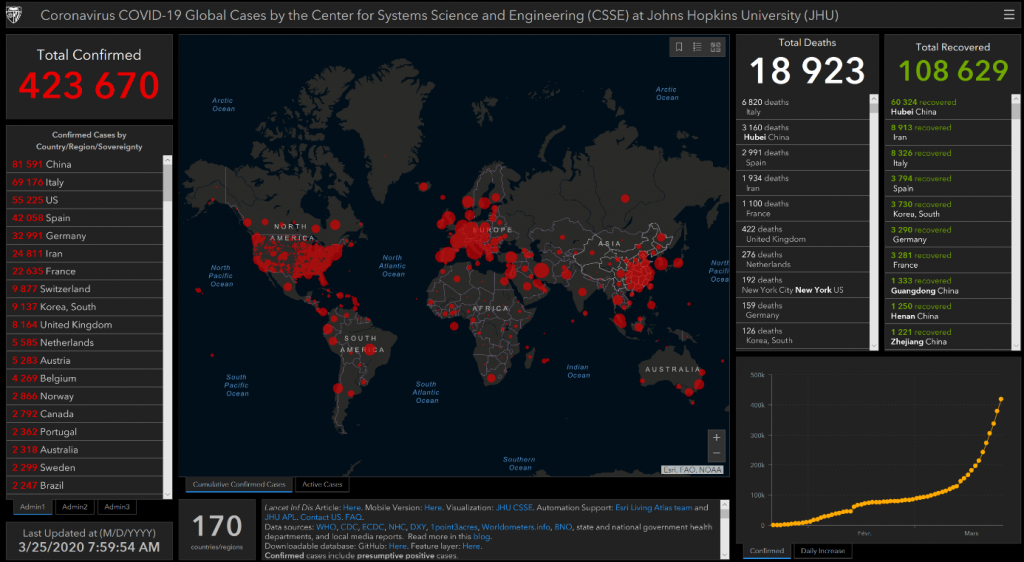
Il s’agit bien sûr d’une ressource essentielle pour les données brutes et tous les autres sites Web publiant des graphiques sur ce sujet s’y réfèrent. La JHU a par ailleurs mis en ligne sa propre interface de consultation interactive de données. Très axée sur la visualisation cartographique, cette interface est séduisante visuellement, mais laisse finalement les visiteurs assez démunis pour répondre à la question que tout le monde se pose : comment évolue la situation dans mon pays, à quelle durée de confinement peut-on s’attendre, et après combien de victimes ?
De nombreuses autres sources proposent une visualisation plus axée sur la dynamique des nombres de cas et de décès, pays par pays. Pour ne prendre qu’un exemple parmi des milliers d’autres :
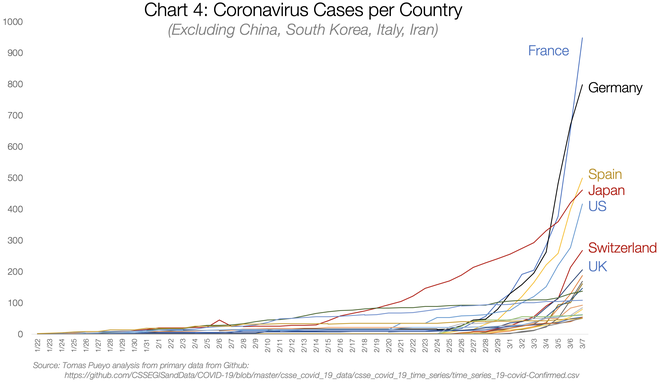
C’est déjà un progrès, car si les courbes sont assez régulières, on peut espérer en tirer des prévisions assez fiables, en les extrapolant sur une durée raisonnable. Encore faut-il choisir pour cela des variables pertinentes et comparées de façon judicieuses entre les différentes sources. Ici, les comparaisons entre pays sont difficilement interprétables. A posteriori, il est d’ailleurs facile de montrer que ce graphe est trompeur : publié le 13 mars, il donnait l’impression que la situation allemande était préoccupante, ce qui a été démenti depuis.
Ces courbes proviennent du blog d’un dénommé Tomas Pueyo, ancien étudiant de Stanford au statut professionnel incertain, qui se présente comme « Creator of viral applications with >20M users. Currently leading a billion-dollar business ». De fait, son talent principal semble être de faire le buzz sur Internet, ce qu’il a parfaitement réussi à faire en l’occurrence (au moment de la traduction en Français, cet article avait déjà été lu 26 millions de fois). France Culture en a fait une critique sévère pour dénoncer ses aspects pseudoscientifiques dans son émission Coronavirus : une épidémie de faux articles scientifiques). Si les objections sur la forme sont judicieuses, cette critique se contente malheureusement d’arguments d’autorité sur le plan scientifique. Il faut aller plus loin pour en comprendre les vraies faiblesses de fond.
Pour cela, il est très éclairant de se pencher sur la meilleure représentation « grand public » que nous avons trouvée : celle du Financial Times
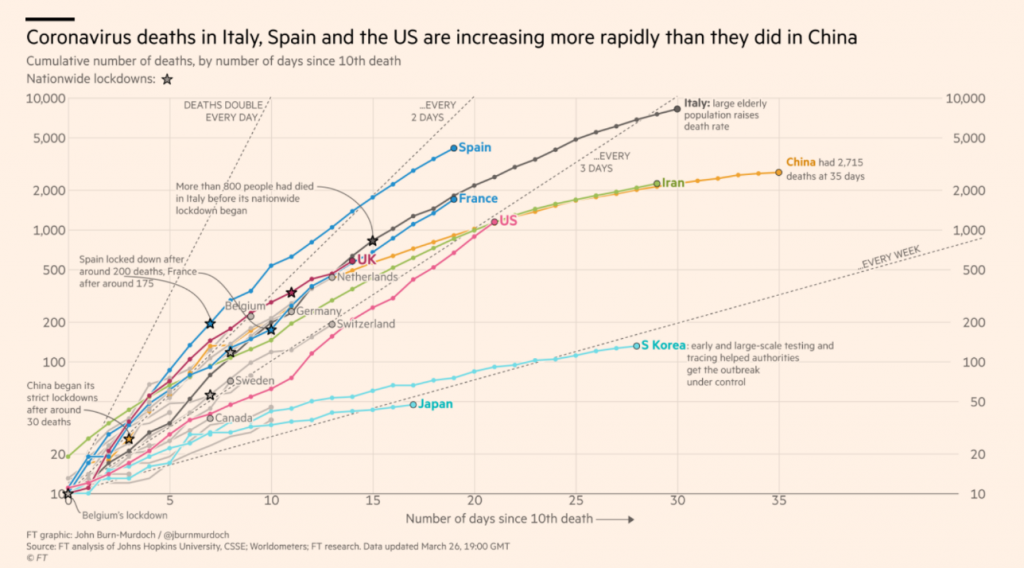
Les comparaisons entre pays paraissent, dans ce graphe, beaucoup plus cohérentes que dans l’article de T. Pueyo. Pourquoi ?
- D’abord parce qu’il traite du nombre de décès, et non du nombre de cas. Les cas identifiés ne sont pas comparables d’un pays à l’autre, car trop dépendants des politiques de dépistage nationales. Même s’il reste sans doute des biais nationaux sur les statistiques à propos des décès, en particulier pour les décès hors hôpital, ils sont probablement beaucoup plus faibles que pour le nombre de cas.
- Les courbes de chaque pays sont recalées par rapport à une même origine (en nombre de jours depuis le 10e décès), ce qui élimine les biais liés aux aléas sur l’espacement des tout premiers cas.
On peut noter qu’avec ce graphique, l’« exception allemande », sur laquelle certains journalistes s’interrogent, disparait complètement : sa courbe des décès est identique à celle de la France et de l’Italie. La faible mortalité apparente est simplement due à sa politique de dépistage massif : à nombre de cas réels égal, les médecins allemands diagnostiquent beaucoup plus de cas confirmés.
Avec ce mode de représentation, les trajectoires par pays paraissent très régulières, sauf pour quelques cas (les États-Unis par exemple). Cette régularité est encore plus frappante quand on regarde les mêmes courbes par foyer épidémique :
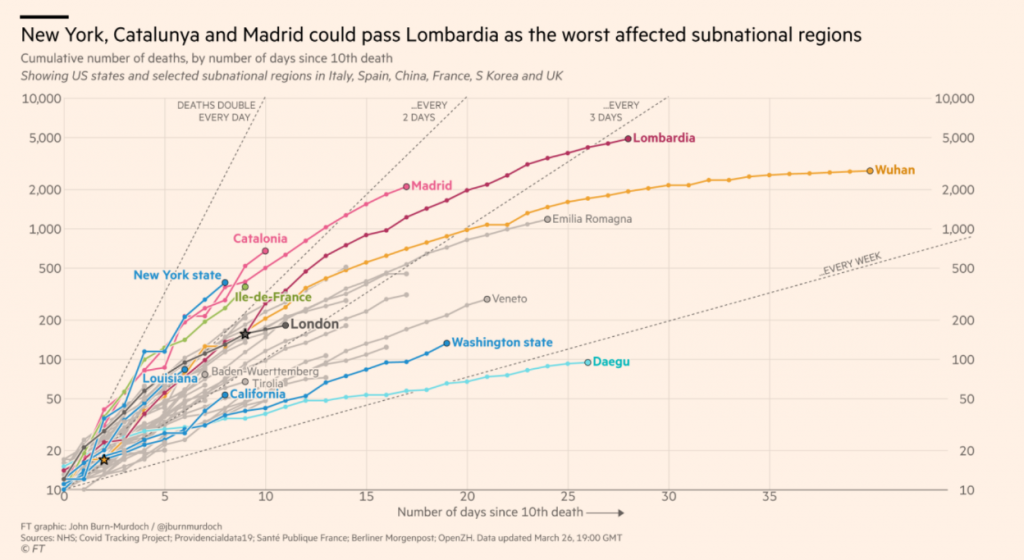
Cette fois, toutes les courbes sont aussi régulières que possible, compte-tenu des aléas journaliers inévitables. On observe aussi de fortes disparités à l’intérieur des pays : voir par exemple la comparaison entre la Lombardie et la Vénétie en Italie. On comprend mieux ainsi l’inflexion de la courbe américaine : elle est due à la montée en puissance du foyer new-yorkais, à la dynamique particulièrement alarmante, alors que le 1er foyer de Washington était plutôt bien contrôlé, à un niveau proche de celui de la Corée du Sud.
Avec des courbes aussi régulières sur des durées de 2 à 3 semaines, on peut commencer à envisager des prévisions raisonnables sur la durée de confinement nécessaire et sur le nombre de victimes potentielles, en s’appuyant sur l’exemple chinois. Sur ce sujet, la France est d’ailleurs particulièrement concernée : elle a débuté avec une trajectoire de type chinois, relativement rassurante. Mais elle dérape depuis le week-end du 21-22 mars vers une trajectoire à l’italienne, avec un risque élevé d’épidémie d’une durée d’au moins 2 mois et d’un nombre de victimes supérieur à 10 000. Sauf si le foyer d’Ile-de-France, actuellement parmi les 4 plus préoccupants au niveau mondial, décline assez vite et n’est pas remplacé par d’autres foyers importants en province.
Des données aux modèles, puis à la décision ?
Un modèle est une représentation « vraie » mais simplifiée de la réalité. Les possibilités d’usage des modèles sont alors liées au degré de simplification. Ainsi une simple probabilité (i.e. proportion de femmes déclarant un cancer du sein après 50 ans) ne peut guère permettre plus que de décider, par exemple, de la mise en place d’un dépistage systématique des femmes à partir d’un âge donné. Parfois de telles prévisions, basées sur une simple mesure ou sur de simples extrapolations de courbes empiriques, qui peuvent être vues comme une variante à peine améliorée de la méthode du « doigt mouillé », sont déjà très utiles. Il faut souvent rester humble et s’en contenter quand on n’a pas de meilleure méthode disponible (d’ailleurs, le doigt mouillé ne marche pas si mal quand le vent est fort !).
Les modèles épidémiologiques dont sont issues les courbes de développement potentiel de l’épidémie sont déjà des modèles plus complexes qui mixent à la fois processus biologiques et statistiques. On a beaucoup vu dans la presse, sous l’intitulé « Flattening the curve » un modèle utilisé pour justifier les mesures de confinement, afin d’éviter la saturation des systèmes de santé :
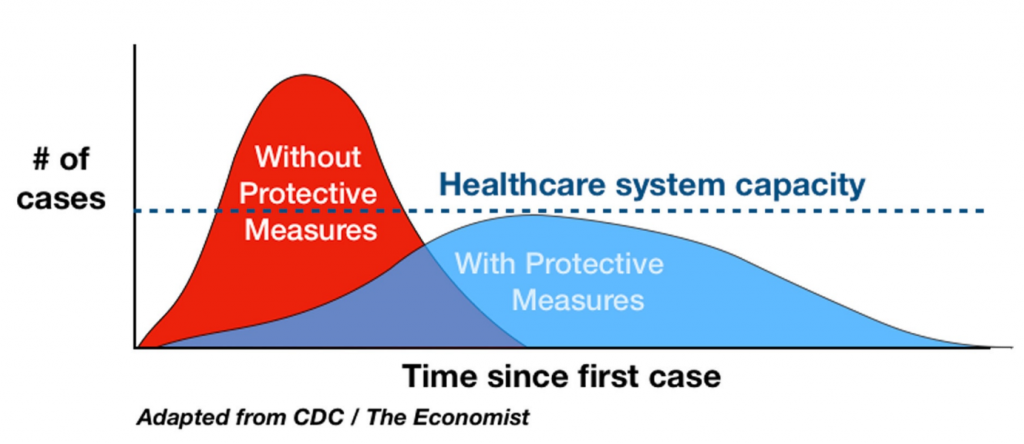
Le modèle à l’origine de ces graphes est tout à fait sérieux. Il est d’ailleurs disponible en ligne sur Modeling COVID-19 Spread vs Healthcare Capacity : chacun peut ainsi le manipuler à loisir. Toutefois, ses auteurs rappellent bien qu’il s’agit d’un modèle théorique destiné à la recherche et à l’éducation, et dont les usages dans l’aide à la décision restent limités pour l’instant. En effet, ce modèle utilise 13 paramètres, dont la plupart ne sont pas encore connus avec précision pour le COVID-19. De plus, ce modèle ne prend pas en compte l’effet des différents degrés de confinement sur ces paramètres pour la simple raison qu’ils ne sont pas encore connus non plus. Bien évidemment, il faudra analyser longuement les données de cette première pandémie, quand elle sera terminée, pour en tirer des leçons. Pour autant ce modèle théorique a déjà permis d’infléchir et/ou d’orienter nombre de décisions prises à travers le monde.
Le modèle évoqué ci-dessus permet dès maintenant de poser une question intéressante, soulevée par le blogueur Josha Bach sur le même site medium.com que Tomas Pueyo : s’il se confirme que le confinement est très efficace pour faire baisser le nombre de victimes, il risque potentiellement de prolonger l’épidémie pendant une durée considérable, ce qui renforcerait l’urgence de mettre au point un vaccin :
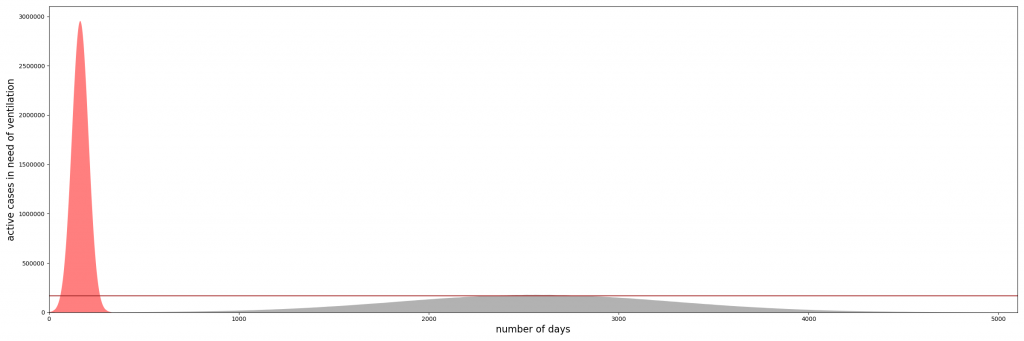
Mais, là encore, tout dépend de la valeur réelle des paramètres pour le COVID-19, encore bien incertains. Ainsi, avec d’autres valeurs de paramètres, l’Imperial College de Londres arrive à une conclusion bien différente : les chercheurs anglais ont évalué différentes stratégies d’atténuation, qui donnent des résultats très différents en termes de nombre de victimes, mais qui influent peu sur la durée de l’épidémie (2,5 à 3,5 mois dans toutes les hypothèses), et donc sur l’impact économique du confinement. Il faut d’ailleurs rendre justice à Josha Bach, qui a eu l’honnêteté de signaler ce travail dans une mise à jour de son post :
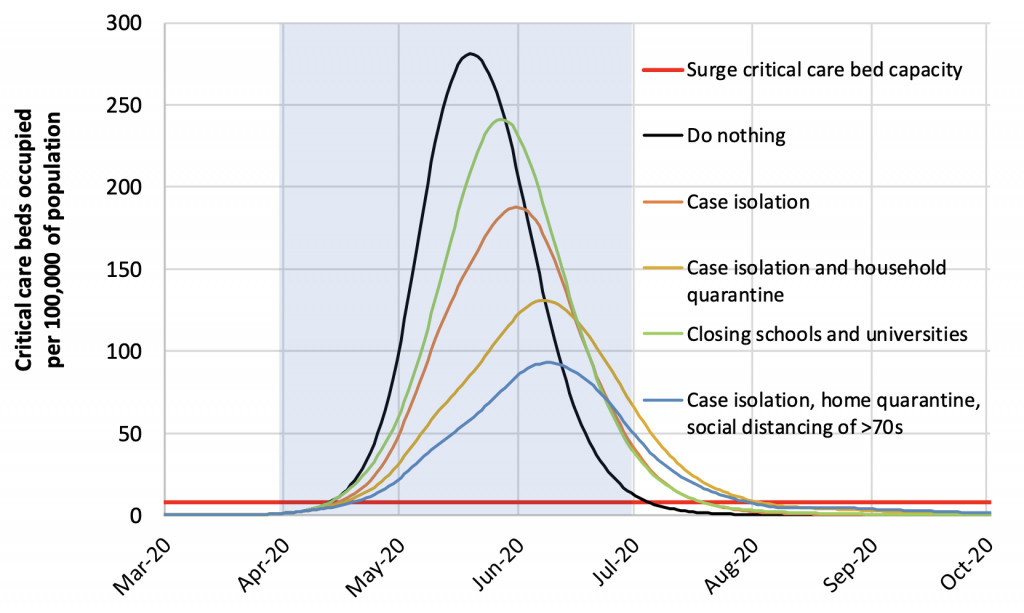
Il est probable que ces simulations ont beaucoup joué sur le changement de cap du Premier Ministre anglais, tenté un moment par la stratégie d’immunisation collective, puis revenu à une stratégie de confinement plus classique. Tout ceci montre que la modélisation, même sans connaître tous les paramètres, peut être d’une grande utilité !
Les exemples évoqués ci-dessus permettent de prendre des décisions « collectives ». Pour autant, au niveau individuel, si les décisions collectives peuvent permettre de rassurer, les attentes sont avant tout personnelles : « est-ce que moi, j’ai un risque ou non d’attraper le virus et d’en mourir ? ». Face à une telle question, seuls les modèles les plus détaillés, reposant sur l’intégration de toutes les connaissances disponibles, permettent, non pas de répondre avec certitude à la question, mais de s’en approcher. On appelle ces modèles des « modèles mécanistes » (process based models), c’est-à-dire basés sur les processus biologiques mis en œuvre et non pas sur des statistiques. Ils font parti du domaine de l’IA symbolique et sont actuellement mis en œuvre en agriculture avec un certain succès par la société itk.
Quelles leçons pour la Data Science ?
L’histoire des connaissances sur le COVID-19 commence tout juste à se construire et il faut rester prudent sur ce sujet. Mais ce petit tour non exhaustif des illustrations courant sur le Web montre déjà quelques tendances intéressantes :
- La Data Intelligence, c’est-à-dire l’art d’organiser la Data de façon à la rendre intelligible, est essentielle pour maitriser le flot de données auxquelles accèdent les scientifiques et les citoyens. Elle peut orienter fortement l’interprétation des phénomènes et un manque de rigueur peut vite entrainer des erreurs facilement détectables après coup… mais trop tard !
- C’est bien une discipline en soi : il est révélateur que ce soit un journal financier qui présente les courbes les plus éclairantes, et non un site médical. Ce n’est sans doute pas un hasard : les financiers sont habitués à analyser des séries temporelles pour y déceler de façon empirique des régularités, ou à l’inverse des points d’inflexion. Cette compétence s’avère finalement plus importante, au moins à cette étape des connaissances sur l’épidémie, que les compétences médicales
- La modélisation est essentielle pour prendre le relais pour proposer une aide à la décision basée sur des prédictions fiables. A ce stade, les compétences métier (en l’occurrence médicales) redeviendront nécessaires. Mais nous n’en sommes pas encore là pour le COVID-19.
Une autre évidence commence à émerger : dans cette phase « post-épidémique », les données collectées seront vitales pour affiner les modèles. Une évaluation fiable du nombre de cas, basée sur le dépistage, sera essentielle pour évaluer la mortalité réelle et mesurer l’effet de l’ampleur et de la précocité du confinement. Sur ce sujet, la France se trouvera cruellement démunie par rapport à des pays comme l’Allemagne et la Corée du Sud.
Philippe Stoop, directeur R&D d’itk et Eric Jallas, Président d’itk
Bonjour,
Relayé avec compliments :
http://seppi.over-blog.com/2020/03/covid-19-data-intelligence-et-modelisation-le-difficile-passage-de-la-donnee-a-l-information-et-a-la-prevision-de-mm.philippe-stoop
Bonjour
le site https://ourworldindata.org/coronavirus propose des visus intéressantes, en particulier en proposant des échelles log.
Ce qui devrait être compris de la situation actuelle, à mon avis, est qu’en fait, compte tenu de la complexité du problème, nous avons très peu de données, bien moins que ce qui serait nécessaire à une statistique sérieuse.
Bonjour,
merci pour cet article !
L’aspect « régulier » des courbes proposées par le Financial Times est beaucoup dû au fait que l’axe des ordonnées est en échelle log, ce qui n’est pas le cas sur le graphique de Tomas Pueyo.
Le lien vers le modèle « flattening the curve » ne fonctionne plus. Un autre lien intéressant sur modélisatiob et COVID : https://twitter.com/Francois_JAULIN/status/1239282536750166018
Bonne journée,
Nathalie
Pour aller plus loin sur le sujet : https://www.nature.com/articles/d41586-020-01812-9